**_GPU-Driven Rendering Performance: Traditional vs Mesh Shaders_**
**William Gunawan** - 26 November, 2025
# Introduction
This technical article is a benchmark comparison of traditional rendering pipelines against modern GPU-driven techniques: draw indirect, mesh shaders, and task shaders.
The focus is on measuring the performance impact of moving culling decisions from CPU to GPU, and from per-instance to per-meshlet granularity.
## Code Availability
The code for this vulkan application is readily available at:
- https://github.com/Williscool13/MeshTaskBenchmark
The profiler results and images used in this article are also readily available at:
- https://github.com/Williscool13/Williscool13.github.io/tree/main/technical/task-mesh-benchmarking
## Test Scene
**Geometry:** 125 Stanford Bunnies (72,378 vertices, 144,046 triangles each) arranged in a 5x5x5 grid.
I had initially intended on drawing 1000 bunnies in a 10x10x10 grid, but performance with the traditional pipeline was too poor for this to be a fair comparison.
**Meshlets:** Generated using [meshoptimizer](https://github.com/zeux/meshoptimizer) - 64 vertices, 64 triangles per meshlet
**Hardware:** AMD Radeon RX 7900 XT
**Model Source:** [Stanford Bunny - Casual Effects](https://casual-effects.com/data/)

## Pipeline Configurations
| Configuration | Per-Instance Culling | Per-Meshlet Culling |
|--------------------------|----------------------|---------------------|
| Traditional | - | - |
| Indirect + Traditional | Yes | - |
| Task and Mesh | - | Yes |
| Indirect + Task and Mesh | Yes | Yes |
**Culling techniques:** Frustum culling (instances and meshlets) + cone-based backface culling (meshlets only)
**Note:** This workload heavily favors instanced rendering (125 copies of one mesh). Scenes with unique geometry per instance would show different characteristics.
# Implementation
## Traditional Pipeline
The traditional pipeline processes vertices through the fixed-function input assembly stage.
A single `vkCmdDrawIndexed` call renders all 125 instances with no culling:
```````````````````````````````````````````````````````````````````
vkCmdDrawIndexed(
cmd,
model.indexCount, // 144,046 triangles = 432,138 indices (144,046 * 3).
125,
model.indexOffset,
model.vertexOffset,
0
);
```````````````````````````````````````````````````````````````````
The vertex shader transforms each vertex using per-instance transforms accessed via `gl_InstanceIndex`:
```````````````````
[shader("vertex")]
VertexOutput vertexMain(Vertex inVertex, uniform PushConsts pushConstants, uint32_t instanceIndex : SV_VulkanInstanceID) {
Instance i = pushConstants.instanceBuffer->instances[instanceIndex];
Model m = pushConstants.modelBuffer->models[i.modelIndex];
Primitive p = pushConstants.primitiveBuffer->primitives[i.primitiveIndex];
MaterialProperties mt = (*pushConstants.materialBuffer).materials[p.materialIndex];
VertexOutput output;
vec4 worldPos = m.modelMatrix * vec4(inPosition, 1.0);
output.position = pushConstants.sceneData->viewProj * worldPos;
// ... other vertex properties
return output;
}
```````````````````
This serves as the baseline - all geometry is processed every frame regardless of visibility.
## Indirect Traditional
This configuration adds GPU-driven per-instance culling while keeping the traditional vertex pipeline.
A compute shader performs frustum culling and writes draw commands for visible instances to an indirect buffer.
The compute shader dispatches one thread per instance to evaluate visibility. Here, we only cull on an instance-level using frustum culling.
```````````````````cpp
vkCmdFillBuffer(cmd, indirectCountBuffer.handle,offsetof(IndirectCount, drawCount), sizeof(uint32_t), 0);
uint32_t groupsX = (125 + 63) / 64;
vkCmdDispatch(cmd, groupsX, 1, 1);
```````````````````
The shader:
```````````````````
// Frustum Cull
bool frustumCullSphere(Frustum frustum, float4 sphere) {
// sphere.xyz = center, sphere.w = radius
// I assume this loop is unrolled by the compiler, but the difference is negligible anyway.
for (int i = 0; i < 6; i++) {
float4 plane = frustum.planes[i];
float dist = dot(plane.xyz, sphere.xyz) + plane.w;
if (dist < -sphere.w) {
return false;
}
}
return true;
}
[numthreads(64, 1, 1)]
void computeMain(uniform ComputePushConst pushConstants, uint3 dtid : SV_DispatchThreadID) {
uint instanceID = dtid.x;
Instance inst = pushConstants.instanceBuffer->instances[instanceID];
if (inst.bIsAllocated == 0) { return; }
MeshletPrimitive prim = pushConstants.primitiveBuffer->primitives[inst.primitiveIndex];
Model model = pushConstants.modelBuffer->models[inst.modelIndex];
float4 boundingSphere = prim.boundingSphere;
float3 worldCenter = mul(model.modelMatrix, float4(boundingSphere.xyz, 1.0)).xyz;
float4 worldBounds = float4(worldCenter, boundingSphere.w);
if (!frustumCullSphere(pushConstants.sceneData->frustum, worldBounds)) {
return;
}
VkDrawIndexedIndirectCommand cmd;
cmd.indexCount = prim.indexCount;
cmd.firstIndex = prim.firstIndex;
cmd.vertexOffset = prim.vertexOffset;
cmd.instanceCount = 1;
cmd.firstInstance = instanceId;
uint outputIndex = pushConstants.indirectCount->drawCount.add(1);
pushConstants.indirectBuffer->commands[outputIndex] = cmd;
}
```````````````````
The compute shader atomically increments `drawCount` and writes `VkDrawIndexedIndirectCommand` structs only for visible instances.
Note: Each visible instance generates a separate draw call with `instanceCount = 1`.
While this simplifies indirect buffer generation (no batching logic needed),
it doesn't leverage hardware instancing for identical geometry.
A more optimized approach would batch identical models into single draws with instanceCount > 1.
The GPU reads the culled draw commands without CPU involvement. We're going all-in on GPU-Driven Rendering:
```````````````````cpp
vkCmdBindVertexBuffers(cmd, 0, 1, &megaVertexBuffer.handle, &vertexOffset);
vkCmdBindIndexBuffer(cmd, megaIndexBuffer.handle, 0, VK_INDEX_TYPE_UINT32);
vkCmdDrawIndexedIndirectCount(
cmd,
traditionalIndirectBuffer.handle,
sizeof(glm::vec4),
traditionalIndirectBuffer.handle,
0,
125,
sizeof(VkDrawIndexedIndirectCommand)
);
```````````````````
Fixed-function input assembly stage is still used for the vertex shader.
The vertex shader uses `firstInstance` to index into the instance buffer:
```````````````````
[shader("vertex")]
VertexOutput vertexMain(
Vertex vertex,
uniform PushConsts pushConstants,
uint instanceId : SV_StartInstanceLocation) // Maps to firstInstance
{
Instance instance = pushConstants.instanceBuffer->instances[instanceId];
Model model = pushConstants.modelBuffer->models[instance.modelIndex];
Primitive primitive = pushConstants.primitiveBuffer->primitives[instance.primitiveIndex];
MaterialProperties materialProperties = pushConstants.materialBuffer->materials[primitive.materialIndex];
float4 worldPos = mul(model.modelMatrix, float4(vertex.position, 1.0));
VertexOutput output;
output.position = mul(pushConstants.sceneData->viewProj, worldPos);
output.worldPos = worldPos.xyz;
// ... other attributes
return output;
}
```````````````````
The Key difference from the baseline is that traditional draws 125 instances unconditionally. Indirect draws 0-125 instances based on GPU culling results.
## Task and Mesh
The task+mesh shader is set up to not be too different from the traditional rendering. We still have instances, models, and primitives.
Each meshlet is described by their offset and count in the meshlet buffer and additionall a cone representing its triangle normals (axis + cutoff angle), generated during meshlet creation.
Each task group processes `TASK_SHADER_DISPATCH_X` number of meshlets.
Each task thread evaluates a meshlet for visibility through occlusion and cone facing direction culling and adds valid meshlets to a shared payload.
Thread 0 dispatches the mesh shader with all meshlets that pass the checks.
Each mesh shader group generates a meshlet's mini vertex and index buffer.
Generally the more complicated your mesh shaders and shading code, the more there is to be gained from meshlet-level culling.
Only a single command needs to be executed on the CPU. Much like the traditional approach, without instance-level culling we are able to instance-draw all meshes by specifying `groupCountY` to the number of instance we're drawing.
The dispatch uses Y dimension for instances: each row of task groups processes one instance's meshlets.
groupCountX handles meshlet chunks, groupCountY = 125 processes all instances in parallel.
```````````````````
uint32_t numChunks = (bunnyModel.meshletCount + (64 - 1)) / 64;
vkCmdDrawMeshTasksEXT(cmd, numChunks, 125, 1);
vkCmdEndRendering(cmd);
```````````````````
Frustum culling is the same as above, and here is the backface culling code:
```````````````````
// Backface Cull
float3 worldConeAxis = normalize(mul((float3x3)model.modelMatrix, mlet.coneAxis));
float3 cameraToCenter = worldCenter - pushConstants.sceneData->cameraWorldPos.xyz;
float centerDist = length(cameraToCenter);
// dot(center - camera, axis) >= cutoff * dist + radius
if (dot(cameraToCenter, worldConeAxis) >= mlet.coneCutoff * centerDist + mlet.meshletBoundingSphere.w) {
visible = false; // Backface culled
}
```````````````````
Because the task shader has interthread communication, we'll need to use a few groupshared synchronization steps.
```````````````````
public struct Meshlet
{
public float4 meshletBoundingSphere;
public float3 coneApex;
public float coneCutoff;
public float3 coneAxis;
public uint32_t vertexOffset;
public uint32_t meshletVerticesOffset;
public uint32_t meshletTriangleOffset;
public uint32_t meshletVerticesCount;
public uint32_t meshletTriangleCount;
};
const static int32_t TASK_SHADER_DISPATCH_X = 64;
struct MeshletPayload {
uint32_t modelIndex;
uint32_t materialIndex;
uint32_t groupMeshletOffset;
uint8_t meshletIndices[TASK_SHADER_DISPATCH_X];
};
groupshared MeshletPayload sharedPayload;
groupshared Atomic visibleMeshletCount;
[shader("task")]
[numthreads(TASK_SHADER_DISPATCH_X, 1, 1)]
void taskMain(uniform PushConsts pushConstants,
uint3 gid : SV_GroupID, uint3 gtid : SV_GroupThreadID)
{
uint32_t instanceId = gid.y;
Instance inst = pushConstants.instanceBuffer->instances[instanceId];
if (inst.bIsAllocated == 0) { return; }
MeshletPrimitive prim = pushConstants.primitiveBuffer->primitives[inst.primitiveIndex];
Model model = pushConstants.modelBuffer->models[inst.modelIndex];
if (gtid.x == 0) {
visibleMeshletCount.store(0);
sharedPayload.modelIndex = inst.modelIndex;
sharedPayload.materialIndex = prim.materialIndex;
sharedPayload.groupMeshletOffset = prim.meshletOffset + (gid.x * TASK_SHADER_DISPATCH_X);
}
GroupMemoryBarrierWithGroupSync();
// Payload must stay under 108 bytes for optimal performance
// uint8_t meshletIndices[64] vs uint32_t saves 192 bytes
// See https://developer.nvidia.com/blog/using-mesh-shaders-for-professional-graphics/
uint8_t meshletID = (uint8_t)gtid.x;
uint localMeshletCount = min(TASK_SHADER_DISPATCH_X, prim.meshletCount - (gid.x * TASK_SHADER_DISPATCH_X));
if (meshletID < localMeshletCount) {
bool visible = !frustumCullSphere(...) && !isBackfacing(...);
if (visible) {
uint index = visibleMeshletCount.add(1);
sharedPayload.meshletIndices[index] = meshletID;
}
}
GroupMemoryBarrierWithGroupSync();
if (gtid.x == 0) {
uint count = visibleMeshletCount.load();
DispatchMesh(count, 1, 1, sharedPayload);
}
}
```````````````````
The mesh shader:
```````````````````
[shader("mesh")]
[outputtopology("triangle")]
[numthreads(MESH_SHADER_DISPATCH_X, 1, 1)]
void meshMain(
in payload MeshletPayload inPayload,
out indices uint3 triangles[MAX_PRIMITIVES], out vertices VertexOutput vertices[MAX_VERTICES],
uint3 gid : SV_GroupID, uint3 gtid : SV_GroupThreadID,
uniform PushConsts pushConstants)
{
uint32_t payloadMeshletIndex = gid.x;
uint32_t meshletIndex = inPayload.groupMeshletOffset + inPayload.meshletIndices[payloadMeshletIndex];
Meshlet meshlet = pushConstants.meshletBuffer->meshlets[meshletIndex];
Model m = pushConstants.modelBuffer->models[inPayload.modelIndex];
float4x4 viewProj = pushConstants.sceneData->viewProj;
SetMeshOutputCounts(meshlet.meshletVerticesCount, meshlet.meshletTriangleCount);
uint32_t threadIndex = gtid.x;
for (uint i = threadIndex; i < meshlet.meshletVerticesCount; i += MESH_SHADER_DISPATCH_X) {
vertices[i] = ...
}
for (uint i = threadIndex; i < meshlet.meshletTriangleCount; i += MESH_SHADER_DISPATCH_X) {
triangle[i] = ...;
}
```````````````````
## Indirect Task and Mesh
The indirect task + mesh shader setup is largely similar to the task mesh setup. There is simply an indirect step before it that culls all instances not visible.
Additionally, instance data is written right next to the dispatch command, allowing the compute pass to specify draw parameters for the task shader to use.
I'm particularly proud about this implementation :)
```````````````````
public struct MeshIndirectDrawParameters {
// indirect parameters
public uint32_t groupCountX;
public uint32_t groupCountY;
public uint32_t groupCountZ;
public uint32_t padding;
// instance/primitive properties
public uint32_t modelIndex;
public uint32_t materialIndex;
public uint32_t meshletOffset;
public uint32_t meshletCount;
};
public struct MeshIndirectParameterBuffer {
public Atomic meshIndirectCount;
uint32_t padding0;
uint32_t padding1;
uint32_t padding2;
public MeshIndirectDrawParameters[] parameters;
}
[numthreads(64, 1, 1)]
void computeMain(uniform ComputePushConst pushConstants, uint3 dtid : SV_DispatchThreadID) {
uint instanceID = dtid.x;
Instance inst = pushConstants.instanceBuffer->instances[instanceID];
if (inst.bIsAllocated == 0) { return; }
MeshletPrimitive prim = pushConstants.primitiveBuffer->primitives[inst.primitiveIndex];
Model model = pushConstants.modelBuffer->models[inst.modelIndex];
float4 boundingSphere = prim.boundingSphere;
float3 worldCenter = mul(model.modelMatrix, float4(boundingSphere.xyz, 1.0)).xyz;
float4 worldBounds = float4(worldCenter, boundingSphere.w);
if (!frustumCullSphere(pushConstants.sceneData->frustum, worldBounds)) {
return; // Instance culled
}
// Each group processes TASK_SHADER_DISPATCH_X number of meshlets, so if its greater than that we need to do multiple dispatches
uint totalMeshlets = prim.meshletCount;
uint numChunks = (totalMeshlets + (TASK_SHADER_DISPATCH_X - 1)) / TASK_SHADER_DISPATCH_X;
uint commandIndex = pushConstants.meshIndirectBuffer.meshIndirectCount.add(1);
pushConstants.meshIndirectBuffer.parameters[commandIndex].groupCountX = numChunks;
pushConstants.meshIndirectBuffer.parameters[commandIndex].groupCountY = 1;
pushConstants.meshIndirectBuffer.parameters[commandIndex].groupCountZ = 1;
pushConstants.meshIndirectBuffer.parameters[commandIndex].modelIndex = inst.modelIndex;
pushConstants.meshIndirectBuffer.parameters[commandIndex].materialIndex = prim.materialIndex;
pushConstants.meshIndirectBuffer.parameters[commandIndex].meshletOffset = prim.meshletOffset;
pushConstants.meshIndirectBuffer.parameters[commandIndex].meshletCount = prim.meshletCount;
}
```````````````````
With some modification to the task shader to accommodate indirect
```````````````````
[shader("task")]
[numthreads(TASK_SHADER_DISPATCH_X, 1, 1)]
void taskMain(uniform PushConsts pushConstants,
uint3 gid : SV_GroupID, uint3 gtid : SV_GroupThreadID, uint drawIndex : SV_DrawIndex)
{
MeshIndirectDrawParameters indirectParameters = pushConstants.meshIndirectParameterBuffer->parameters[drawIndex];
if (gtid.x == 0) {
visibleMeshletCount.store(0);
sharedPayload.modelIndex = indirectParameters.modelIndex;
sharedPayload.materialIndex = indirectParameters.materialIndex;
sharedPayload.groupMeshletOffset = indirectParameters.meshletOffset + (gid.x * TASK_SHADER_DISPATCH_X);
}
GroupMemoryBarrierWithGroupSync();
// ... culling and payload population same as non-indirect version
}
```````````````````
Much like the indirect draw for traditional rendering, this also has the limitation of having one indirect draw per instance, rather than batched instance dispatching.
The resulting draw commands are executed using the following dispatch
```cpp
vkCmdPushConstants(cmd, indirectTaskMeshGraphics.pipelineLayout.handle, VK_SHADER_STAGE_TASK_BIT_EXT | VK_SHADER_STAGE_MESH_BIT_EXT | VK_SHADER_STAGE_FRAGMENT_BIT, 0,
sizeof(Renderer::IndirectTaskMeshRenderPushConstant), &pushData2);
vkCmdDrawMeshTasksIndirectCountEXT(
cmd,
meshletIndirectBuffer.handle,
offsetof(MeshIndirectParameterBuffer, parameters),
meshletIndirectBuffer.handle,
offsetof(MeshIndirectParameterBuffer, meshIndirectCount),
125,
sizeof(MeshIndirectDrawParameters)
);
vkCmdEndRendering(cmd);
```
## Meshlet Generation
Meshlets are generated using [meshoptimizer](https://github.com/zeux/meshoptimizer) with the following configuration:
**Parameters:**
- 64 vertices per meshlet (max)
- 64 triangles per meshlet (max)
- Cone culling angle: 0 degrees
**Process:**
1. Build meshlets from the original mesh using `meshopt_buildMeshlets()`
- Splits geometry into fixed-size clusters
- Each meshlet gets its own micro-vertex and micro-triangle indices
2. Optimize micro-indices with `meshopt_optimizeMeshlet()`
- Improves cache locality within each meshlet
- Reorders vertices/triangles for better GPU performance
3. Compute bounds using `meshopt_computeMeshletBounds()`
- Bounding sphere (center + radius) for frustum culling
- Normal cone (apex, axis, cutoff) for backface culling
**Cone Culling:** Each meshlet stores a normal cone representing the spread of its triangle normals. If the entire cone faces away from the camera, all triangles in the meshlet are backfacing and can be culled as a group. This is distinct from per-triangle backface culling in the rasterizer.
**Stanford Bunny Stats:**
- 72,378 vertices, 144,046 triangles
- Traditional: 1 draw call
- Meshlet: 2,251 meshlets

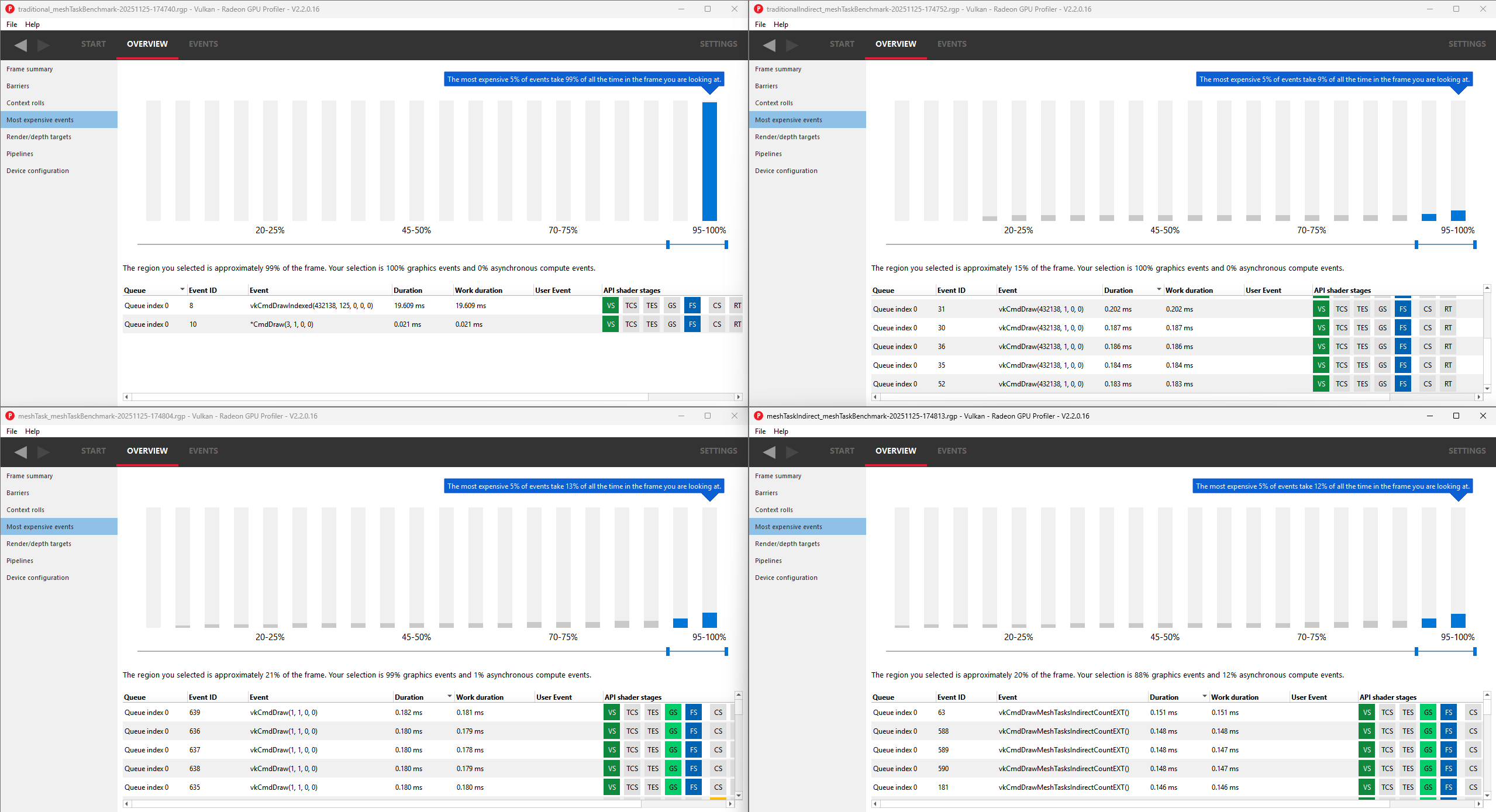
# Results
All tests were performed with the camera positioned to view nearly the entire 125-instance grid.
Frame times were measured until the framerate generally stabilized at 2560x1440 resolution in immediate present mode.
| Pipeline Configuration | Average FPS | Relative Performance |
|------------------------|-------------|----------------------|
| Traditional | 50.8 | 1.00x (baseline) |
| Indirect + Traditional | 74.0 | 1.46x |
| Task + Mesh | 269.5 | 5.30x |
| Indirect + Task + Mesh | 269.9 | 5.31x |
# Discussion
(###) **Task and Mesh shaders provide massive gains with only meshlet-level culling**
- Task and Mesh achieves a 5.3x performance increase over traditional vertex pipeline
- Processing 2,251 meshlets per instance vs full 72K vertex model
(###) **Instance-level culling shows mixed results**
- Indirect + Traditional: 46% faster than baseline (74 FPS vs 51 FPS)
- Traditional rendering processes every vertex regardless of visibility, so eliminating even a few instances provides measurable savings.
- There is a considerable amount of waste in traditional rendering. Lots of backface rasterization, reasonably worse cache locality, and less control overall of the geometry pipeline.
- Indirect + Task + Mesh: Negligible improvement over Task+Mesh (~0.1% difference)
- Culling overhead nearly matches savings in the case of the Task + Mesh Indirect.
- Meshlet-level culling already eliminates most invisible geometry, leaving little for instance culling to optimize.
Task and mesh shaders do exactly what they advertise: they give control of vertex generation to the programmer.
They enable us to process each meshlet independently with tight locality.
The finer granularity results in better GPU occupancy and aligns the graphics pipeline with modern GPU-driven rendering techniques.
More importantly, it allows precise control over which parts of a mesh actually get rendered, eliminating wasted work before it reaches the rasterizer.
## Profiler Analysis
Cache behavior shows clear differences between traditional and mesh shader approaches:
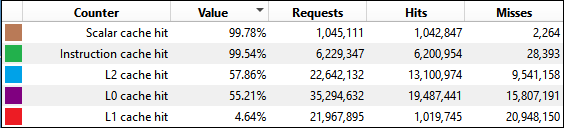
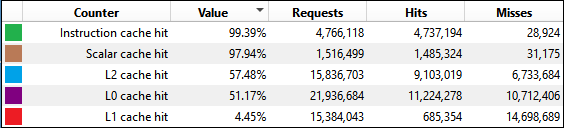
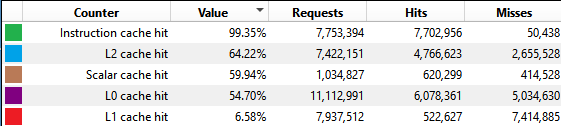
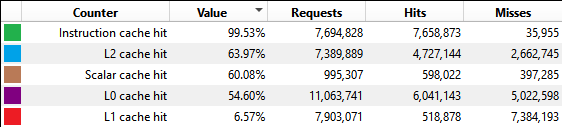
(###) **L2 Cache Performance**
- Traditional: 57.8% hit rate
- Traditional Indirect: 57.4% hit rate
- Mesh: 64.2% hit rate
- Mesh Indirect: 63.9% hit rate
(###) **Observations**
Mesh shaders achieve ~11% better L2 cache hit rates.
This improvement likely stems from processing meshlets as independent, tightly-packed units rather than strided vertex buffers across the entire model.
Notably, adding indirect culling doesn't significantly hurt cache performance in either pipeline. The compute pass overhead is minimal compared to the rendering workload.
(###) **L1 Cache Behavior**
L1 cache hit rates are consistently low across all configurations (4-7%).
This pattern appears in both this benchmark and my game engine, suggesting it may be related to the draw setup or memory access patterns.
While this could affect absolute performance numbers, the relative comparison between pipelines remains valid.
## Limitations
This benchmark favors mesh shaders due to the high vertex count (72K vertices per bunny). The 5.3x speedup reflects ideal conditions for meshlet-level culling.
Other optimizations may also disproportionately improve the performance of traditional rendering techniques, further reducing the performance gap between the 2 approaches.
Geometry LOD for example, would likely help traditional rendering slightly more than it does meshlet rendering.
### Practical Considerations
Other factors that make traditional pipelines more appealing also need to be considered:
- Much better support on older GPUs. Task+Mesh is only supported on NVIDIA Turing+, AMD RDNA2+, and Intel Arc. Traditional pipelines work on any GPU from the past decade.
- Simpler debugging and profiling. Mesh shader workloads can be harder to trace and analyze with standard GPU tools.
- Traditional rendering is much more ubiquitous so learning material and general developer familiarity with them is high.
- Task + Mesh shaders aren't universally beneficial. Low-poly meshes (< 1000 triangles) may not benefit from the added complexity, while high-density photogrammetry scans and CAD models see the largest gains.
# Conclusion
If you're planning on exploring modern rendering techniques for use in your game engine, you need to know the benefits and drawbacks of using them.
Task and mesh shaders are great for scenes with high geometry complexity, but may not perform as well for simple scenes.
Adoption rate is still low, requiring modern hardware from the user. [Vulkan GPU Info](https://vulkan.gpuinfo.org/listextensions.php) reports adoption rates at <10%, so there is still a way to go before this technique can be broadly used.
If you plan on making a game engine or renderer with large reach, this technique may not be the right choice for you.
With all this in mind, if these circumstances are right for you, use task and mesh shader! They're not that complicated.
Thanks for reading! Feel free to contact me for fun talks about graphics and game engines :)
(#) References
- [NVIDIA - Introduction to Mesh Shaders](https://developer.nvidia.com/blog/introduction-turing-mesh-shaders/)
- [AMD - Mesh Shader Guide](https://gpuopen.com/learn/mesh_shaders/mesh_shaders-from_vertex_shader_to_mesh_shader/).
- [NVIDIA - Using Mesh Shaders For Professional Graphics](https://developer.nvidia.com/blog/using-mesh-shaders-for-professional-graphics/)