**_Task and Mesh Shaders: A Practical Guide (Slang)_**
[William Gunawan](https://www.williscool.com)
Written on 2025/12/07
# Introduction
Mesh shaders represent a fundamental shift in GPU rendering pipelines.
Unlike traditional vertex shaders that process vertices individually, mesh shaders adopt a compute-like programming model with explicit thread dispatch and shared memory access.
This article will demonstrate a practical task/mesh shader implementation in Vulkan with Slang, including:
- Trivial Task + Mesh shader implementation (Sascha Willems' Sample)
- Basic mesh shader pipeline
- Task + Mesh shader with frustum and backface culling
For a comprehensive explanation of the mesh shader model, refer to NVIDIA's [Introduction to Mesh Shaders](https://developer.nvidia.com/blog/introduction-turing-mesh-shaders/) and AMD's [Mesh Shader Guide](https://gpuopen.com/learn/mesh_shaders/mesh_shaders-from_vertex_shader_to_mesh_shader/).
For performance comparisons and detailed profiling results, see my [task/mesh shader benchmark](../../technical/task-mesh-benchmarking/task-mesh-benchmarking.md.html), which demonstrates improved cache hit rates and finer culling granularity compared to traditional pipelines.
I assume familiarity with Vulkan basics: pipeline creation, descriptors, and buffer device addresses.
Throughout this article, I access buffer data exclusively through BDAs without using samplers or textures.
Complete source code available on [GitHub](https://github.com/Williscool13/TaskMeshRendering).
## Terminology
**Task Shader / Amplification Shader**
An optional pre-processing stage that determines which mesh shader workgroups to spawn. Performs coarse culling (e.g., per-meshlet frustum culling) before mesh shading.
Typically dispatched with 32-128 threads per workgroup to evaluate multiple meshlets in parallel.
While all threads can `DispatchMesh` for mesh shader workgroups, only one needs to do it after a group shared sync.
Called "Amplification Shader" in DirectX 12.
**Mesh Shader**
Generates primitives and vertices for rasterization.
Replaces the traditional vertex/geometry shader stages.
Outputs a variable number of triangles per workgroup (up to hardware limits, varies by vendor but typically 256 vertices/256 triangles).
Though mesh shaders are not limited to triangles (you can output other primitives), triangles will be the focus of this article.
**Meshlet**
A small cluster of vertices and triangles, typically 32-64 vertices and 64-124 triangles. See why in the tips section of this [article](https://developer.nvidia.com/blog/using-mesh-shaders-for-professional-graphics/).
Meshlets are the atomic unit processed by mesh shaders, designed to fit within GPU shared memory and optimize cache locality.
**Thread / Invocation**
A single execution instance within a thread group.
Threads within a thread group can cooperate via shared memory and barriers.
**Thread Group / Workgroup**
A collection of threads dispatched together, sharing local memory and synchronization primitives.
In task shaders, one workgroup typically evaluates multiple meshlets (often one per thread) and emits mesh shader workgroups for visible ones.
In mesh shaders, one workgroup processes exactly one meshlet.
**Meshlet Backface Culling**
Conservative culling of meshlets whose cone normal indicates all contained triangles face away from the camera.
Not to be confused with traditional per-triangle backface culling in the rasterizer, this operates at meshlet granularity in the task shaders to avoid processing non-visible geometry entirely.
# Basic Task and Mesh Shader (Sascha Willems' Sample)
We'll start with a basic task/mesh shader adapted from Sascha Willems' sample repository. This was where I first looked when implementing task/mesh shader in Vulkan.
While it demonstrates a minimum viable implementation, it lacks enough detail to truly understand task/mesh shader capabilities.
I've adapted the shader a bit to fit my own code, but the general idea is still the same:
`````````````````````` cpp
// Slang
import common;
static const float4 positions[3] = {
float4( 0.0, -1.0, 0.0, 1.0),
float4(-1.0, 1.0, 0.0, 1.0),
float4( 1.0, 1.0, 0.0, 1.0)
};
struct VertexOutput
{
float4 position : SV_Position;
float4 color : TEXCOORD0;
};
struct DummyPayLoad
{
uint dummyData;
};
struct PushConstant {
float4x4 modelMatrix;
SceneData* sceneData;
};
[shader("task")]
[numthreads(1, 1, 1)]
void taskMain()
{
DummyPayLoad localPayload;
DispatchMesh(3, 1, 1, localPayload);
}
[shader("mesh")]
[outputtopology("triangle")]
[numthreads(1, 1, 1)]
void meshMain(out vertices VertexOutput vertices[3], out indices uint3 triangles[1],
uint3 DispatchThreadID : SV_DispatchThreadID, uint3 groupId : SV_GroupID,
uniform PushConstant pushConstant)
{
float4x4 mvp = mul(pushConstant.sceneData.viewProj, pushConstant.modelMatrix);
uint meshletID = groupId.x;
// Hash-based per-meshlet coloring for visualization
uint hash = meshletID * 747796405u + 2891336453u;
float3 color = float3(
(hash & 0xFF) / 255.0,
((hash >> 8) & 0xFF) / 255.0,
((hash >> 16) & 0xFF) / 255.0
);
float4 offset = float4(0.0, 0.0, float(DispatchThreadID.x), 0.0);
SetMeshOutputCounts(3, 1);
for (uint i = 0; i < 3; i++) {
vertices[i].position = mul(mvp, positions[i] + offset);
vertices[i].color = float4(color, 1.0f);
}
triangles[0] = uint3(0, 1, 2);
}
[shader("fragment")]
float4 fragmentMain(VertexOutput input)
{
return input.color;
}
``````````````````````
Let's take a look at the CPU code before further exploring the shader code.
This example is meant to be called from the CPU with:
`````````````````````` cpp
// C++
vkCmdDrawMeshTasksEXT(cmd, 1, 1, 1);
``````````````````````
Fairly simple, we are dispatching a single task shader group.
The pipeline flow:
Task Shader -> Mesh Shader -> Fragment Shader
The dispatched task shader group is hardcoded to spawn 3 mesh shader groups, each processing one "meshlet" (in this case, a single triangle; real meshlets typically contain 32-64 vertices).
However, this example is so trivial you could skip the task shader entirely and just call `vkCmdDrawMeshTasksEXT(cmd, 3, 1, 1)` directly (create the pipeline without a task shader).

This sample is a good start to ensure that task and mesh shaders actually work in your renderer. It fills in a few basic questions like:
- Does my device support Task/Mesh shaders?
- Have I set up my pipeline to draw to my screen correctly?
- Does my shader compilation work correctly for task and mesh shaders?
It also answers some basic questions about how task and mesh shaders work together.
**Task Shader**
- Dispatches N mesh shader groups.
- Only one thread should call DispatchMesh (typically thread 0 after a barrier). Or, all threads can call it with identical parameters
- The dispatch must include a payload, which should contain information for the mesh shader.
The task shader dispatches the mesh shader groups with the command `DispatchMesh(x, y ,z, Payload p)`, which takes 4 parameters.
X, Y, Z dispatch should be familiar to you as the standard compute-shader dispatch style.
The payload communicates data from task to mesh shader. It is syntactically required and empty in this example), but real applications typically use it to pass meshlet indices.
Since task shader threads may cooperatively populate the payload, it requires groupshared synchronization before dispatch.
Payload size significantly impacts performance. [NVIDIA recommends](https://developer.nvidia.com/blog/using-mesh-shaders-for-professional-graphics/) keeping task shader outputs below 236 or 108 bytes, preferring compact data types (uint8_t, uint16_t) when possible.
In my testing, reducing payload size from ~260+ to ~86 bytes improved draw call time from ~0.09ms to ~0.06ms according to GPU profiler measurements, a 33% speedup.
As mentioned above, because of how trivial this example is, the task shader serves no real purpose. If the payload is unused, it is almost always better to just skip the task shader and directly dispatch the mesh shader.
**Mesh Shader**
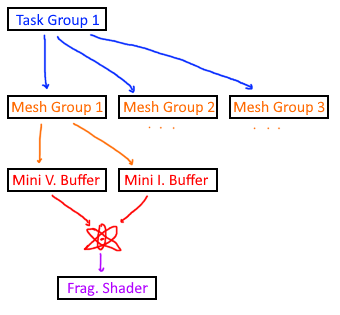
- Each mesh shader group independently constructs a mini-vertex and mini-index buffer to be rasterized and sent to the fragment shader.
- The mesh shader should indicate how many triangles and indices it intends on outputting. This is done with `SetMeshOutputCounts(vertices, triangles)`, and all threads in the mesh shader group must call SetMeshOutputCounts with identical values.
Just to emphasize, each mesh shader group operates on 1 meshlet. This example uses 1 thread per group for simplicity, but production code typically uses 32-128 threads per task group and 32-128 threads per mesh group.
So if a mesh shader has groupsize (32, 1, 1), each of those threads should help populate a single shared mini-vertex and mini-index buffer, that will be used to draw a single meshlet.
For production use, we need:
- Task shader performing actual work (culling, payload construction)
- Clear payload usage patterns
- Mesh shader demonstrating thread cooperation
The next section will explore these points.
# Data Preparation
Mesh shaders operate on meshlets rather than individual vertices. We use [meshoptimizer](https://github.com/zeux/meshoptimizer) to partition our mesh and generate the required data structures.
For deeper explanation of meshlet theory and generation algorithms, see meshoptimizer's documentation.
(##) Meshlet Generation
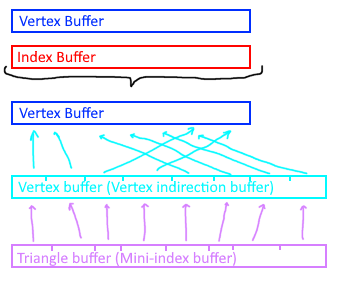
The core function is `meshopt_buildMeshlets`, which takes vertex and index buffers and outputs three separate buffers:
- **Meshlet Vertices** (uint32_t) - Indices into the vertex buffer
- **Meshlet Triangles** (uint8_t) - Indices into meshlet vertices
- **Meshlets** (meshopt_Meshlet) - Meshlet descriptors with culling metadata
Note the indirection: `meshletTriangles` contains indices into `meshletVertices`, which contains indices into the original vertex buffer.
When building meshlets, we specify maximum vertices and triangles per meshlet.
I use 64 vertices and 64 triangles. [NVIDIA recommends](https://developer.nvidia.com/blog/using-mesh-shaders-for-professional-graphics/) 64 vertices with 84-124 primitives for optimal alignment, though these values depend on vertex attributes and shader outputs.
`````````````````````` cpp
// C++
const size_t maxVertices = 64;
const size_t maxTriangles = 64;
size_t max_meshlets = meshopt_buildMeshletsBound(primitiveIndices.size(), maxVertices, maxTriangles);
std::vector meshlets(max_meshlets);
std::vector meshletVertices(primitiveIndices.size());
std::vector meshletTriangles(primitiveIndices.size());
std::vector primitiveVertexPositions;
meshlets.resize(meshopt_buildMeshlets(&meshlets[0], &meshletVertices[0], &meshletTriangles[0],
primitiveIndices.data(), primitiveIndices.size(),
reinterpret_cast(primitiveVertices.data()), primitiveVertices.size(), sizeof(Vertex),
maxVertices, maxTriangles, 0.f));
``````````````````````
For the Stanford Bunny (69,451 vertices), this produces 2,251 meshlets. Individual meshlets vary in size, not all contain the maximum 64 vertices or triangles.
Before generating culling metadata, we optimize each meshlet for GPU cache locality:
`````````````````````` cpp
// C++
// Reorder vertices and triangles within each meshlet for optimal GPU vertex cache utilization
for (auto& meshlet : meshlets) {
meshopt_optimizeMeshlet(&meshletVertices[meshlet.vertex_offset], &meshletTriangles[meshlet.triangle_offset], meshlet.triangle_count, meshlet.vertex_count);
}
``````````````````````
Finally, we generate culling metadata and package everything into our GPU-friendly struct. Meshoptimizer's `meshopt_computeMeshletBounds` provides the bounding sphere and cone data needed for culling:
`````````````````````` cpp
// C++
struct Meshlet
{
glm::vec4 meshletBoundingSphere;
glm::vec3 coneApex;
float coneCutoff;
glm::vec3 coneAxis;
uint32_t vertexOffset;
uint32_t meshletVerticesOffset;
uint32_t meshletTriangleOffset;
uint32_t meshletVerticesCount;
uint32_t meshletTriangleCount;
};
// Generate bounds and extract into my meshlet data structure
for (meshopt_Meshlet& meshlet : meshlets) {
meshopt_Bounds bounds = meshopt_computeMeshletBounds(
&meshletVertices[meshlet.vertex_offset],
&meshletTriangles[meshlet.triangle_offset],
meshlet.triangle_count,
reinterpret_cast(primitiveVertices.data()),
primitiveVertices.size(),
sizeof(Vertex)
);
meshletModel.meshlets.push_back({
.meshletBoundingSphere = glm::vec4(bounds.center[0], bounds.center[1], bounds.center[2],bounds.radius), // Frustum/Backface Culling
.coneApex = glm::vec3(bounds.cone_apex[0], bounds.cone_apex[1], bounds.cone_apex[2]), // Backface Culling
.coneCutoff = bounds.cone_cutoff, // Backface Culling
.coneAxis = glm::vec3(bounds.cone_axis[0], bounds.cone_axis[1], bounds.cone_axis[2]), // Backface Culling
.vertexOffset = vertexOffset,
.meshletVerticesOffset = meshletVertexOffset + meshlet.vertex_offset,
.meshletTriangleOffset = meshletTrianglesOffset + meshlet.triangle_offset,
.meshletVerticesCount = meshlet.vertex_count,
.meshletTriangleCount = meshlet.triangle_count,
});
}
``````````````````````
The use of culling properties will be discussed later when culling is implemented in the task shader.
# Basic Mesh Shader Pipeline
If a task shader performs no culling or meaningful preprocessing, it adds unnecessary overhead. This section demonstrates mesh shaders in isolation, we'll add task shader culling in the next section.
Our mesh shader accesses all meshlet data through buffer device addresses in push constants:
```````````````````````` cpp
// Slang
struct PushConstant {
float4x4 modelMatrix;
SceneData* sceneData;
VertexData* vertexBuffer;
MeshletVerticesData* meshletVerticesBuffer;
MeshletTrianglesData* meshletTrianglesBuffer;
MeshletData* meshletBuffer;
};
````````````````````````
A mesh shader *group* (not individual thread) processes one meshlet and outputs its vertices/triangles.
Each thread within the group cooperates to populate the output buffers. In this example without task shaders, we use `SV_GroupID.x` to determine which meshlet to process.
```````````````````````` cpp
// Slang
const static int32_t MESH_SHADER_DISPATCH_X = 32;
const static uint MAX_VERTICES = 64;
const static uint MAX_PRIMITIVES = 64;
[shader("mesh")]
[outputtopology("triangle")]
[numthreads(MESH_SHADER_DISPATCH_X, 1, 1)]
void meshMain(
out indices uint3 triangles[MAX_PRIMITIVES], out vertices VertexOutput vertices[MAX_VERTICES],
uint3 groupId : SV_GroupID, uint3 gtid : SV_GroupThreadID,
uniform PushConstant pushConstant)
{
uint meshletIdx = groupId.x;
Meshlet meshlet = pushConstant.meshletBuffer->meshlets[meshletIdx];
float4x4 viewProj = pushConstant.sceneData->viewProj;
uint hash = meshletIdx * 747796405u + 2891336453u;
float3 color = float3(
(hash & 0xFF) / 255.0,
((hash >> 8) & 0xFF) / 255.0,
((hash >> 16) & 0xFF) / 255.0
);
SetMeshOutputCounts(meshlet.meshletVerticesCount, meshlet.meshletTriangleCount);
uint32_t instanceIndex = gtid.x;
for (uint i = instanceIndex; i < meshlet.meshletVerticesCount; i += MESH_SHADER_DISPATCH_X) {
uint localVertexIndex = pushConstant.meshletVerticesBuffer->meshletVertices[meshlet.meshletVerticesOffset + i].vertexIndex;
Vertex v = pushConstant.vertexBuffer->vertices[meshlet.vertexOffset + localVertexIndex];
float4 worldPos = mul(pushConstant.modelMatrix, float4(v.position, 1.0));
float4 clipPos = mul(viewProj, worldPos);
vertices[i].position = clipPos;
vertices[i].color = float4(color, 1.0);
}
for (uint i = instanceIndex; i < meshlet.meshletTriangleCount; i += MESH_SHADER_DISPATCH_X) {
uint triOffset = meshlet.meshletTriangleOffset + i * 3;
uint idx0 = pushConstant.meshletTrianglesBuffer->meshletTriangles[triOffset + 0].triangleIndex;
uint idx1 = pushConstant.meshletTrianglesBuffer->meshletTriangles[triOffset + 1].triangleIndex;
uint idx2 = pushConstant.meshletTrianglesBuffer->meshletTriangles[triOffset + 2].triangleIndex;
triangles[i] = uint3(idx0, idx1, idx2);
}
}
````````````````````````
The fragment shader simply outputs the interpolated color (omitted for brevity).
In the shader code, each thread in a group specifies that the work group will be outputting `meshletVerticesCount` vertices and `meshletTriangleCount` indices. Then each thread works to populate the mini-buffers.
With 32 threads per group but up to 64 vertices per meshlet, threads use a strided pattern where each thread processes multiple vertices:
| Thread | Iteration 0 | Iteration 1 |
|--------|-------------|-------------|
| 0 | v0 | v32 |
| 1 | v1 | v33 |
| 2 | v2 | v34 |
| ... | ... | ... |
| 31 | v31 | v63 |
The vertex loop first fetches the vertex indirection index from the meshlet vertex buffer, and uses that to index into the real vertex buffer. The resulting vertex is then processed into the output mini-vertex buffer like a normal vertex shader would.
The triangle loop will then simply forward the triangle indices from the meshlet buffer, fairly straightforward.
We dispatch one mesh shader group per meshlet, which is 2,251 groups total for the Stanford Bunny:
```````````````````````` cpp
// Slang
MeshOnlyPipelinePushConstant pushData{
.modelMatrix = stanfordBunny.transform.GetMatrix(),
.sceneData = currentSceneDataBuffer.address,
.vertexBuffer = vertexBuffer.address,
.meshletVerticesBuffer = meshletVerticesBuffer.address,
.meshletTrianglesBuffer = meshletTrianglesBuffer.address,
.meshletBuffer = meshletBuffer.address,
};
vkCmdPushConstants(cmd, meshOnlyPipeline.pipelineLayout.handle, VK_SHADER_STAGE_MESH_BIT_EXT, 0, sizeof(MeshOnlyPipelinePushConstant), &pushData);
vkCmdDrawMeshTasksEXT(cmd, stanfordBunny.meshlets.size(), 1, 1);
````````````````````````
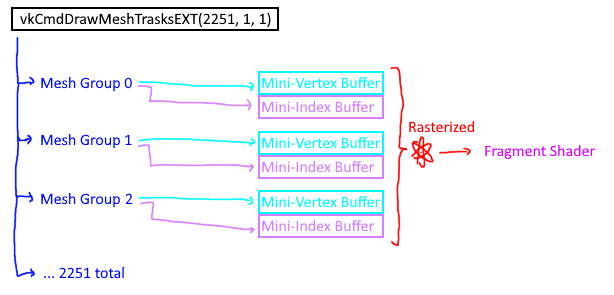

This works well, but still renders every meshlet regardless of visibility. This is where task shaders come in.
# Adding Task Shaders and Culling
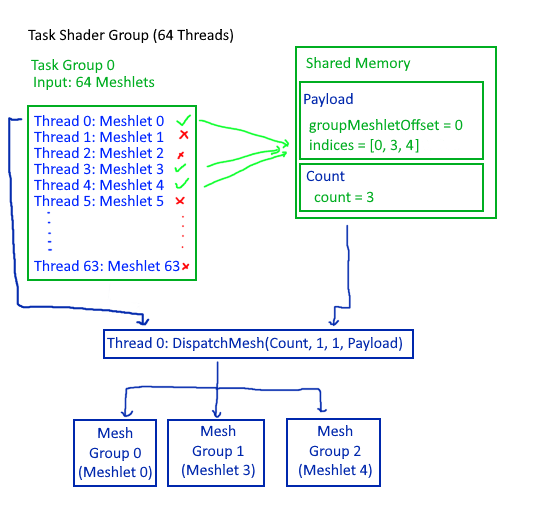
Task shaders preprocess meshlets before spawning mesh shader groups, enabling GPU-driven culling without CPU involvement. Each task shader group evaluates multiple meshlets (64 in this implementation) and only dispatches mesh shaders for visible ones.
(##) Task Shader Workflow
The task shader performs two jobs:
1. Cull invisible meshlets using frustum and backface tests
2. Build a payload containing indices of visible meshlets for the mesh shader
```````````````````````` cpp
// Slang
const static int32_t TASK_SHADER_DISPATCH_X = 64;
struct MeshletPayload {
uint32_t groupMeshletOffset; // Base meshlet index for this group
uint8_t meshletIndices[64]; // Worst case: all 64 meshlets visible, need all slots
};
groupshared MeshletPayload sharedPayload;
groupshared Atomic visibleMeshletCount;
````````````````````````
This payload uses 68 bytes by storing local offsets as uint8_t instead of full uint32_t indices, well under NVIDIA's 236-byte recommendation.
(##) Culling Implementation
Each thread in the task shader evaluates one meshlet:
```````````````````````` cpp
// Slang
[shader("task")]
[numthreads(TASK_SHADER_DISPATCH_X, 1, 1)]
void taskMain(uint3 gid : SV_GroupID, uint3 gtid : SV_GroupThreadID,
uniform PushConstant pushConstant)
{
uint32_t groupMeshletOffset = (gid.x * TASK_SHADER_DISPATCH_X);
uint32_t totalMeshlets = pushConstant.meshletCount;
// Initialize shared memory (thread 0 only)
if (gtid.x == 0) {
visibleMeshletCount.store(0);
sharedPayload.groupMeshletOffset = groupMeshletOffset;
}
GroupMemoryBarrierWithGroupSync();
// Handle partial groups (e.g., group 36 processes only 11 meshlets)
uint8_t threadMeshletOffset = (uint8_t)gtid.x;
uint groupMeshletCount = min(TASK_SHADER_DISPATCH_X, totalMeshlets - groupMeshletOffset);
if (threadMeshletOffset < groupMeshletCount) {
uint32_t meshletIndex = groupMeshletOffset + threadMeshletOffset;
Meshlet meshlet = pushConstant.meshletBuffer->meshlets[meshletIndex];
// Each thread tests one meshlet
bool visible = frustumCull(...) && backfaceCull(...);
if (visible) {
uint index = visibleMeshletCount.add(1);
sharedPayload.meshletIndices[index] = gtid.x; // Local offset (≤64, fits in uint8_t)
}
}
GroupMemoryBarrierWithGroupSync();
// Thread 0 dispatches mesh shaders for visible meshlets only
if (gtid.x == 0) {
DispatchMesh(visibleMeshletCount.load(), 1, 1, sharedPayload);
}
}
````````````````````````
| Thread | Meshlet Index | Frustum Test | Backface Test | Result |
|--------|---------------|--------------|---------------|--------------------------|
| 0 | 0 | Pass | Pass | Visible, payload[0] = 0 |
| 1 | 1 | Fail | - | Culled |
| 2 | 2 | Pass | Fail | Culled |
| 3 | 3 | Pass | Pass | Visible, payload[1] = 3 |
| ... | ... | ... | ... | ... |
Note that threads populate the payload in parallel, so visible meshlets may not appear in sequential order, hence the use of an atomic counter to track the next available slot.
Frustum Culling tests the meshlet's bounding sphere against all 6 frustum planes. If the sphere is outside any plane, the entire meshlet is culled.
```````````````````````` cpp
// Slang
bool frustumVisible = true;
for (uint i = 0; i < 6; i++) {
// Plane equation: dot(point, normal) + distance
// If sphere center is farther than -radius from plane, it's visible
float dist = dot(pushConstant.sceneData.frustum.planes[i].xyz, worldBounds.xyz) + pushConstant.sceneData.frustum.planes[i].w;
frustumVisible &= (dist >= -worldBounds.w);
}
````````````````````````
Backface Culling uses meshoptimizer's cone data. The cone normal represents the average normal of all triangles in the meshlet. If the entire cone faces away from the camera, we cull the meshlet:
```````````````````````` cpp
// Slang
// From meshoptimizer documentation - backface/cone culling formula
// Transform cone axis to world space (model may be rotated/scaled)
float3 worldConeAxis = normalize(mul((float3x3)pushConstant.modelMatrix, meshlet.coneAxis));
float3 cameraToCenter = worldCenter - pushConstant.sceneData->cameraWorldPos.xyz;
float cameraToCenterDist = length(cameraToCenter);
bool backfaceVisible = dot(cameraToCenter, worldConeAxis) < meshlet.coneCutoff * cameraToCenterDist + meshlet.meshletBoundingSphere.w;
````````````````````````
(##) Mesh Shader Changes
The mesh shader remains nearly identical to the mesh-only version. The key difference is receiving the payload to determine which meshlet to process:
```````````````````````` cpp
// Slang
[shader("mesh")]
void meshMain(in payload MeshletPayload sharedPayload, ...)
{
// Payload contains only visible meshlet indices
uint meshletIdx = sharedPayload.groupMeshletOffset + sharedPayload.meshletIndices[groupId.x];
// Rest is identical to mesh-only version
Meshlet meshlet = pushConstant.meshletBuffer->meshlets[meshletIdx];
...
}
````````````````````````
(##) CPU Dispatch
```````````````````````` cpp
// C++
vkCmdPushConstants(...);
uint32_t taskGroupCount = (meshletCount + 63) / 64;
vkCmdDrawMeshTasksEXT(cmd, taskGroupCount, 1, 1);
````````````````````````
We dispatch one task shader group per 64 meshlets. For the Stanford Bunny (2,251 meshlets), this is 36 task shader groups. Each group culls its assigned meshlets and spawns only the necessary mesh shader groups.
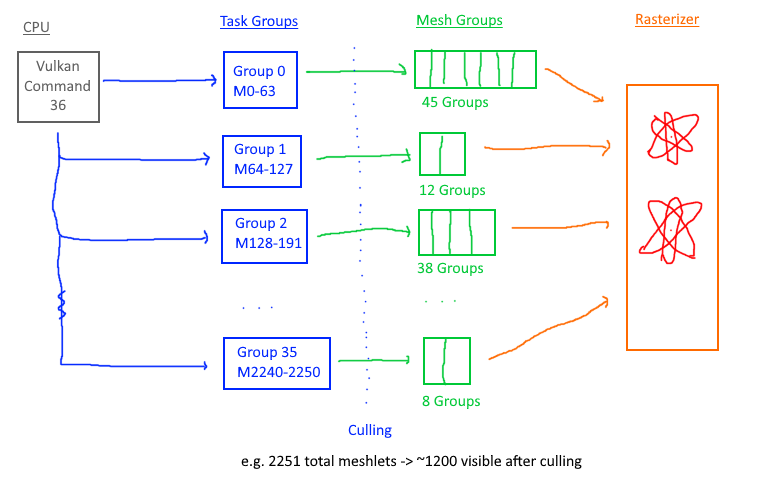
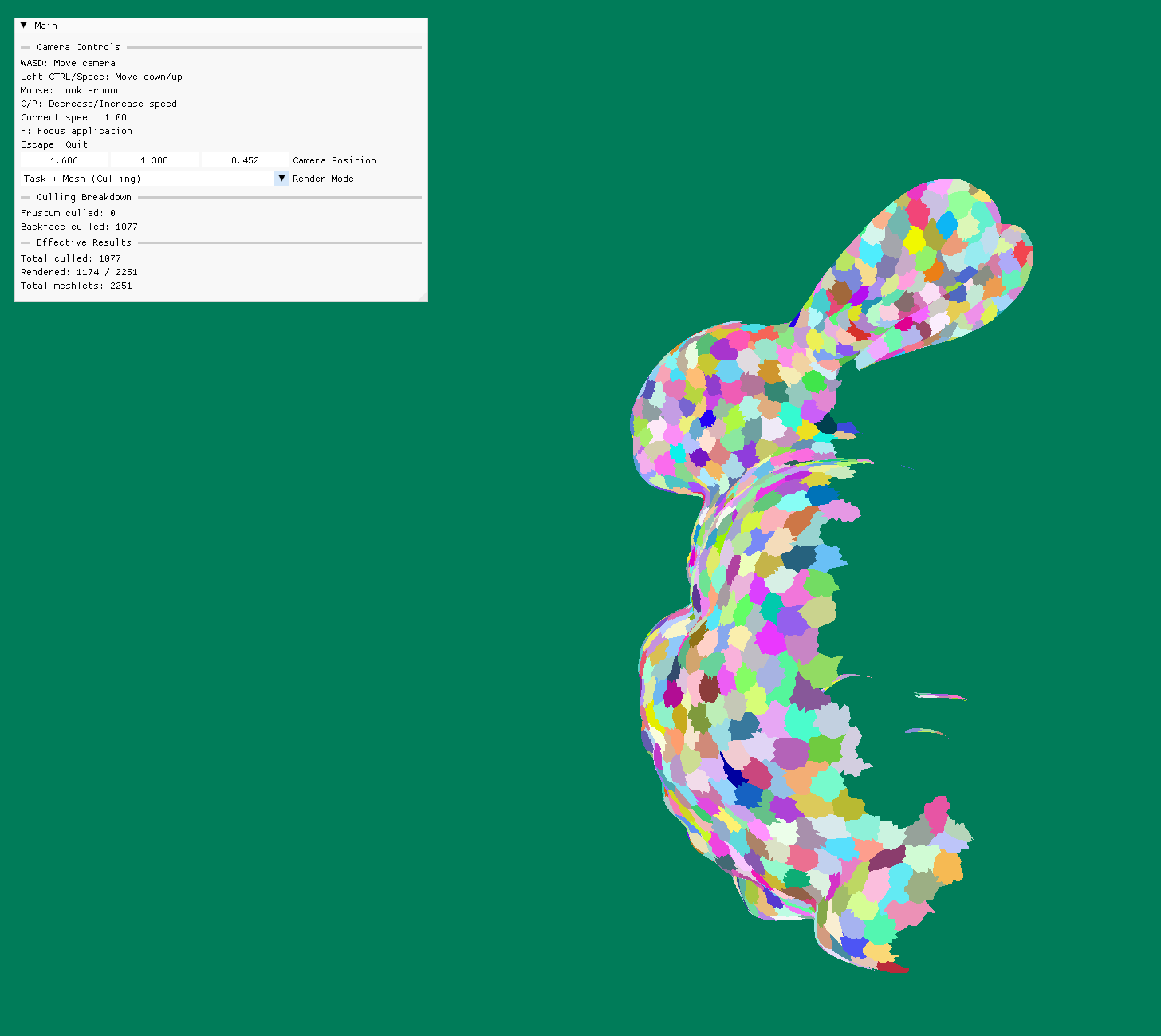
For a static camera view of the Stanford Bunny, frustum and backface culling typically eliminates 40-60% of meshlets, reducing vertex processing and rasterization workload significantly.

# Conclusion
This article demonstrated a practical task and mesh shader implementation in Vulkan, progressing from a minimal example to a production-ready pipeline with GPU-driven culling.
Task shaders enable meshlet-level frustum and backface culling entirely on the GPU. For the Stanford Bunny test scene, this approach typically culls 40-60% of meshlets before vertex processing, significantly reducing rasterization workload.
Complete source code with build instructions is available on [GitHub](https://github.com/Williscool13/TaskMeshRendering).
For further exploration, consider combining task/mesh shaders with indirect draws for fully GPU-driven rendering, or extending the culling system with occlusion queries.
Thanks for reading!